







SURVIVE
A VR tool to help patients with stimulant use disorder stay in recovery

TOOL-VAN
A system for easier deep learning verification to build confidence in autonomous systems

OPEN
An AI-driven system forecasting critical mineral supply, demand, and global trends

CACHE
A cybersecurity architecture using compartmentalization to stop threats at source

JobDESIGNER
A talent management tool that simplifies job analysis, recruitment, and training.

PLATO
A personalized learning assistant that tailors training to match available resources
ENHANCE
Improving biomedical data tools through user-centered, human-AI-focused design.
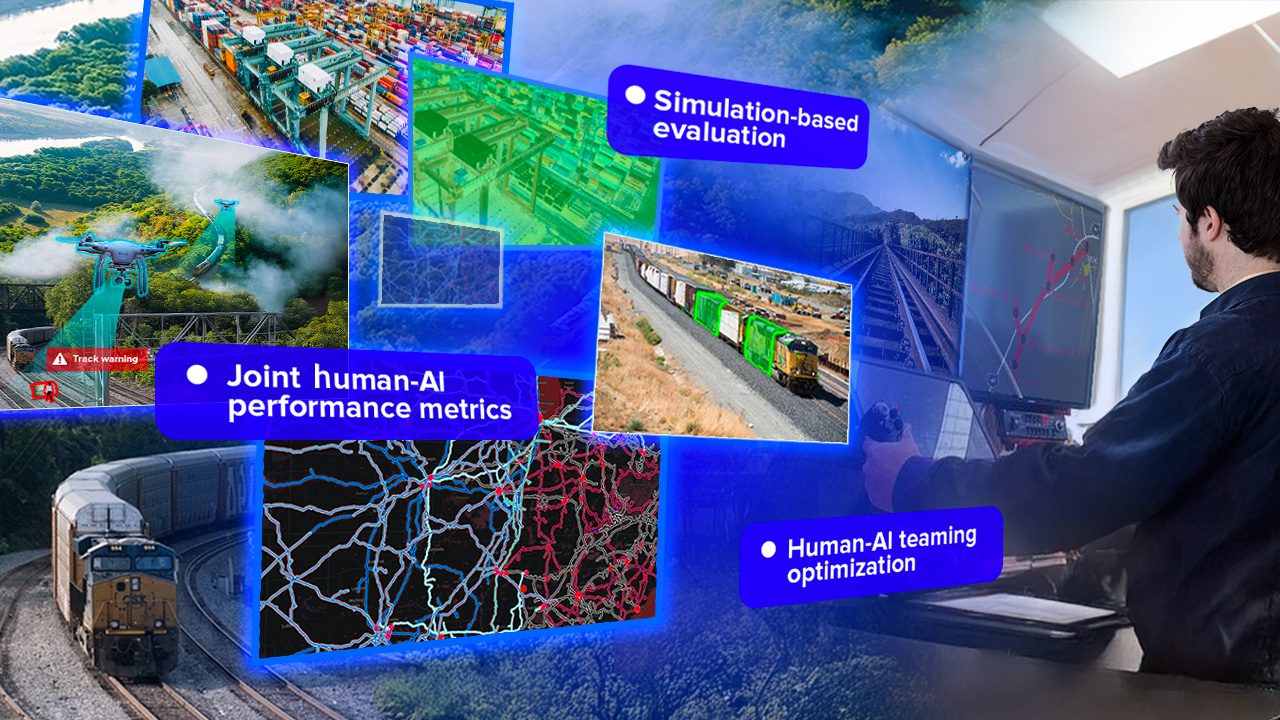
ABOARD
A testing framework to improve railroad safety through human-AI interaction analysis

PAL
Human-robot interface to build trust and interpret speech, gestures, and gaze